How We Turned Two Failures into a $2,500 MRR
Success
Hello! What’s your background, and what are you working on?
Hello there, my name is Pierre de Wulf. I'm 27 and I currently live in Paris. I'm the co-founder of ScrapingBee, a web-scraping API that handles proxies, CAPTCHA solving, and headless browsers for you so you won't be blocked ever again while scraping the web.
Before focusing full time on ScrapingBee I spent the last 12 months building products with my lifelong friend and co-founder, Kevin Sahin. Before that I was working as a data engineer for a successful startup, recently acquired, which specialized in real-estate data management. And before that, I spent most of my time at the university in France. I also spent a year doing web development in Boston.
So you tried to build successful products for 12 months before starting ScrapingBee. What happened?
So basically everything began two years ago. I was still working full time and Kevin had just left his job. I talked to Kevin about this great app idea my girlfriend had. She wanted to be able to manage all the items she was interested in buying online in one place.
We thought the idea was interesting and decided to do it as a side project. At the time Kevin was writing his Java web scraping handbook and I had a full-time job.
Three weeks later, ShopToList was born. You could add products from any site on the web and receive a daily notification about any price drop. I've known Kevin for 15 years, and we had countless side project ideas together, but ShopToList was the first time we actually released something useful.
We launched on Product Hunt and Reddit and managed to get around 3,000 signups in two weeks. We were incredibly happy about this.
However, we quickly realized that it would be really hard to transform this side project into a profitable product. But that didn't matter to us; this thing was not very time consuming and we were happy to help real people out there with something we built.
One day, while looking at our database, we noticed three people in ShopToList had more than 1,000 products. After a quick investigation, we discovered that those people were managing e-commerce online and were using ShopToList to monitor their competitor's prices.
After further investigations, we noticed that many tools existed online to monitor prices but we felt that we could do, if not better, at least as good. And this time, we would charge for our product.
While ShopToList was not a success if we only look at the product, we like to think that it was a success if you look at the team. It showed me and Kevin that we were able to build things and work together. This, plus the fact that I wanted to leave my job, was enough for us to decide to build PricingBot, a price-monitoring tool.
In July 2018, I left my job and we officially created our company. We made a landing page that explained PricingBot's purpose and we posted it online in multiple forums and subreddits. We managed to gather 50 email addresses that way and decided to actually build PricingBot.
During the next nine months many things happened. We managed to build PricingBot pretty quickly and to have our first client two days after leaving our free beta. Things were looking great, at first. But we soon encountered three big problems:
- Problem 1: We knew nothing about e-commerce or pricing strategies, which meant that we had trouble understanding what our users wanted and how to reach them
- Problem 2: When you need to set up a price-monitoring system, it's very time-consuming to match your product with your competitors. This meant that before our users could see the value of our product, they had to spend a lot of time setting up their accounts. In the beginning we literally spent 120 hours manually matching one of our client products with its competitors... only for him to churn after one month.
- Problem 3: Our conversion rate was way, way too low. We tried several tactics but never managed to reach even 1%.
Kevin and I were against a wall. Back when we incorporated we wanted to be able to live off our product in 15 months. By the time we realized PricingBot would never have the success we hoped, we only had four months left.
At that point we had two options. We could continue with PricingBot or build something new. We were both tired of doing things that seemed to have little-to-no impact, so we decided to take a short break to come back with a clear mind and, hopefully, some product ideas. As you probably guessed, one of those ideas was ScrapingBee.
What motivated you to get started with ScrapingBee?
It was June 2019 and we wanted to give ourselves one last chance to bootstrap something together. We only needed an idea. During our short retreat, we were able to figure out two things:
- One thing we've always done at our full-time jobs, as well as ShopToList and PricingBot, was web-scraping.
- There are many solutions out there, but none of them solved our problems exactly. Most of the time those solutions were either unreliable, too expensive, or too complex.
For PricingBot, we were using a successful web-scraping service but it was very unreliable. And we thought, if this product is successful, there is no reason ours won't be. And this is basically how things started with ScrapingBee. We tried to solve a pain point we had by crafting a better solution than the existing one.
Because we did a lot of scraping before we knew what problems we needed to address: ours. While scraping one website can be relatively easy, scraping at scale is not for mainly three reasons:
- Having a large pool of proxies is expensive and hard to manage.
- Managing even 10+ instances of headless browser is difficult.
- Maintaining extraction rules for multiples websites is hard and time-consuming.
Our competitors and our past working experience had already validated the idea. We pulled together a landing page and posted it everywhere (I really suggest you take a look at landen for this, an amazing tool crafted by Felix Gurtler). We managed to have 150 emails in half the time it took us to have 50 emails with PricingBot.
Another big point that motivated us to start with ScrapingBee is that this time our targets were developers, like us. And this changed two things. First, we knew how to reach developers. We knew what websites they liked and what subjects they were interested in. Second, Kevin and I both own technical blogs that have around 20,000 visitors per month in total, and we knew we would be able to leverage this traffic to promote ScrapingBee.
We needed to make a call fast, so we decided to go all-in on ScrapingBee.
What went into building the initial product? What was your tech stack?
Because our product is an API, we decided to begin with just one endpoint, one that would return the HTML content of any URL. To craft the dashboard and the payment system we reused what we did for PricingBot. In about a week we were able to something that worked. We chose to deploy our app on Heroku. This choice alone allowed us to be scalable from day one.
However, we quickly realized that numbers between what we would charge for our API and our cost did not add up. We had a scalable solution, but not a profitable one.
Because we were completely bootstrapped we couldn't afford to lose money for every new customer. So we chose to spend three more weeks rebuilding our infrastructure in Heroku, AWS, and bare-metal servers in order to reduce our cost to the minimum.
At the end of July we decided to launch, and sent an email to all our beta testers.
How have you attracted users and grown ScrapingBee?
Building the product was the easiest part. Promoting it was much harder.
Because we had a bit of experience doing it with ShopToList and PricingBot, the first month of promotion was done in three phases.
Phase 1: Link-building and general awareness
The main goal of this phase was to show the internet that our product was live so that when people typed "ScrapingBee" on the web, they'd find us. This phase would help us build a little SEO and, hopefully, bring our first clients.
Our to-do list looked something like this:
- Send an email to all our blog readers, beta testers, and PricingBot users
- Post ScrapingBee to Indie Hackers, and do a milestone post about launching
- Post ScrapingBee in the Facebook groups we were part of
- Talk about ScrapingBee in r/entrepreneur, r/scraping, r/startup
- Post ScrapingBee on as many startup listing sites we could found. (You take a look at this list for example.)
- We also answered lots of Quora questions about scraping
This brought 41 users and two customers.
Phase 2: Building expertise and reaching targeted audience
We decided to go all-in with content marketing. Having both previously worked in web scraping for the last five years, we knew a lot about it. Kevin even wrote a book about it. We noticed that many scraping tools did content marketing, but it was poorly done. It was all posts with the same catchy titles that brought little-to-no value for the reader. You know the titles I'm talking about:
- You won't believe what this Puppetteer function can do?
- 10 scraping tools that will change your life
- OMG, thanks to Selenium, I earned this!
Ok, maybe I am exaggerating a little bit here, but you get the idea. Content marketing seems too often to be done to please Google and not readers.
So anyway, we decided to spend a lot of time on a big blog post that would be some kind of utimate scraping guide. Having already written many answers on Quora, we leveraged that content to write something worth reading. But because we really wanted to make a good post both Kevin and I spent two full days on it.
Once we were happy with our blog post, we decided to post it everywhere we could. It seemed we were right spending so much time on this post because its success exceeded our expectations, especially on Reddit. We published the post on the 30th of July, and in four days, we had almost 13k users visiting our website.
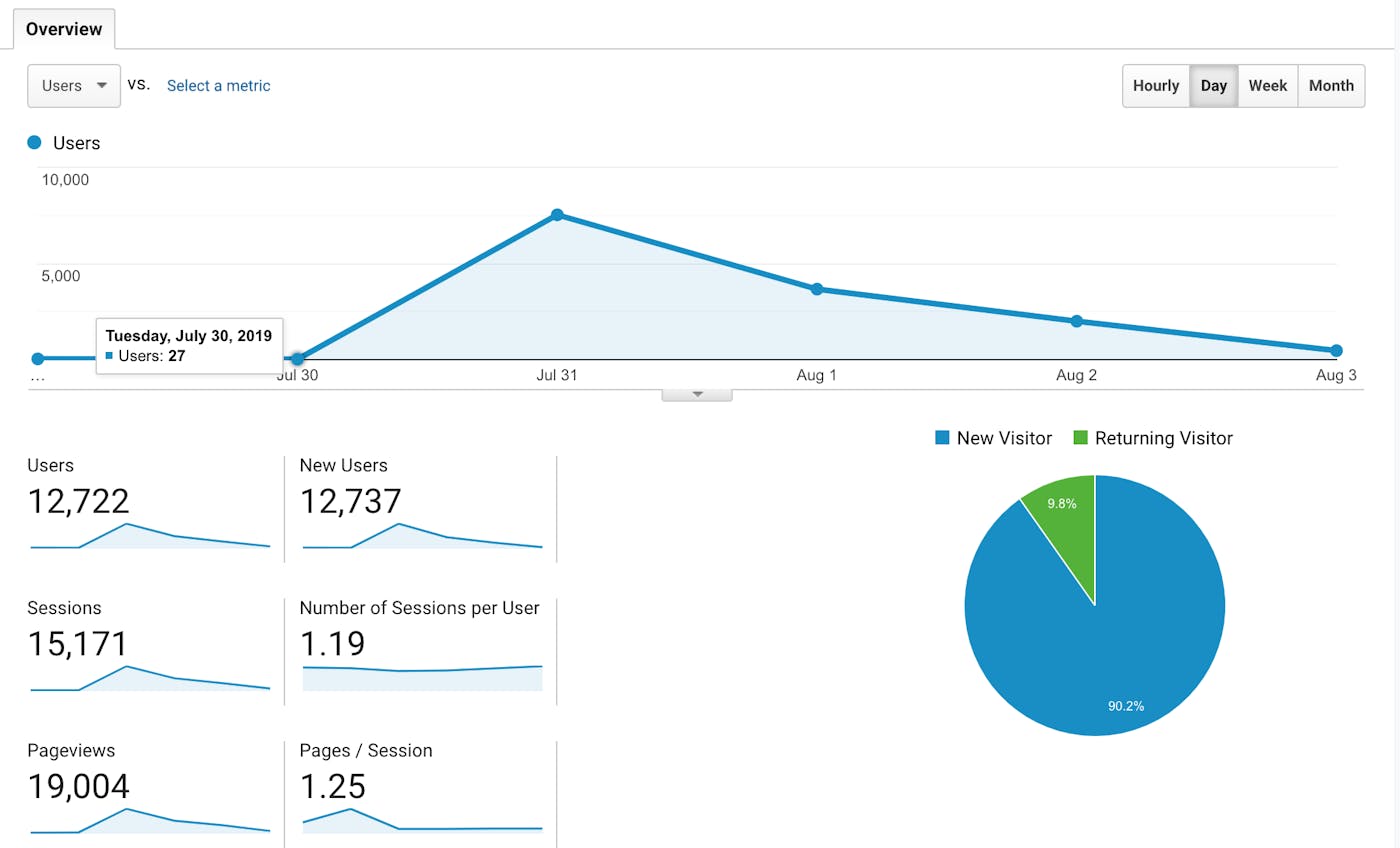
This brought us 60 users and four customers.
Phase 3: Product Hunt
All the traffic from our blog post allowed us to improve our product and landing page a lot. On the 24th of August, we decided to launch on Product Hunt. We ended up 2nd product of the day with almost 400 upvotes.
This, of course, brought a ton of traffic and users to our website: almost 200 users and six customers.
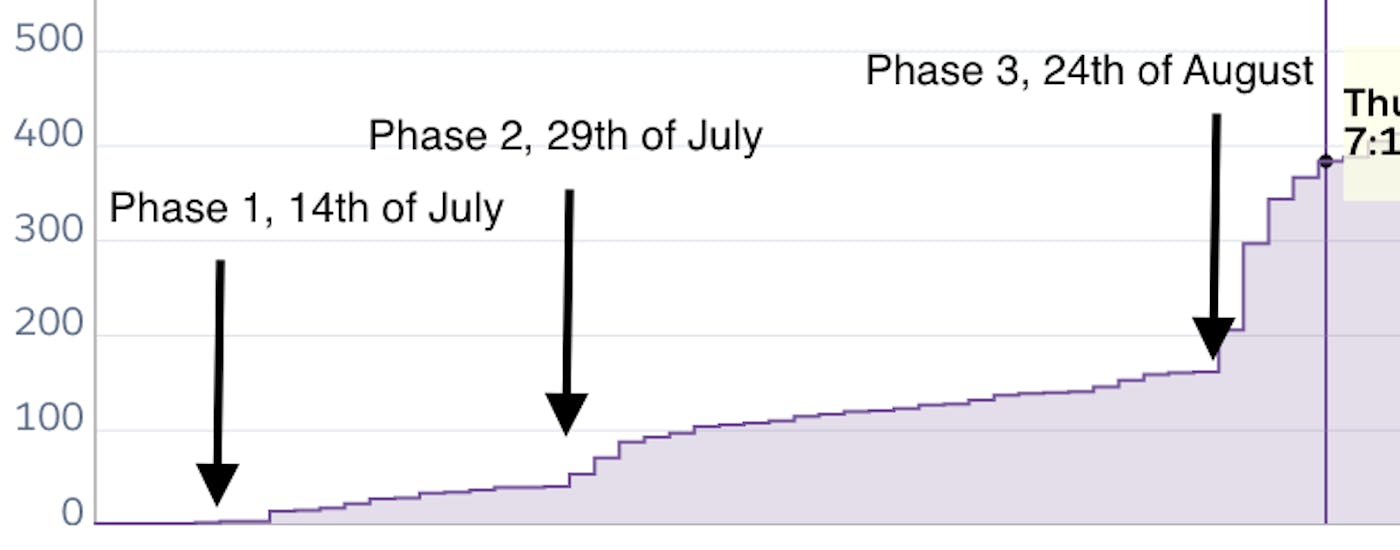
Here's a final graph of the numbers of our early days of growth:
What’s your business model, and how have you grown your revenue?
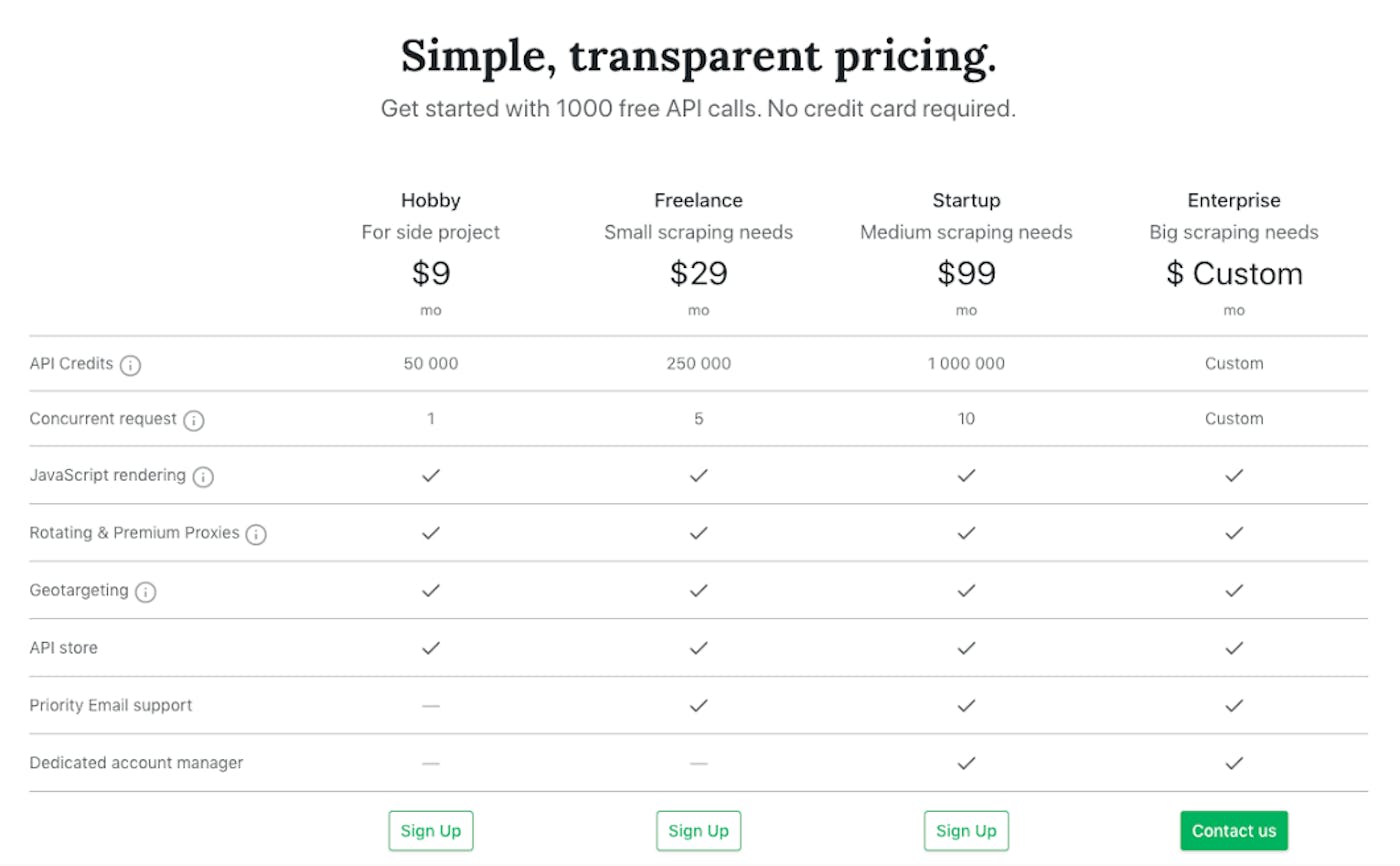
ScrapingBee was completely bootstrapped, so it was very important for us to be profitable from day one. Running an API at scale, especially a scraping API, can be very expensive. In order to maximize revenue and conversion we've made two important decisions regarding pricing.
The first was not to have a very generous free plan. We only offer 1,000 API calls. But our cheapest plan begins at $9. So all things considered, we are generous 😇.
We are happy with the result of this as our conversion rate, from signup to paid plan, is 5%. But it's also true that 45% of our users are on our cheapest plan. We're also happy because we had six customers who first started using our cheapest plan but who ended up upgrading their subscriptions. This week we even had one user who did all the upgrades, starting from $9 to $29, and two days later from $29 to $99.
The second decision was to have our most expensive plan at $99. It meant that if a customer needed more calls than allowed in this plan, they would automatically get a custom plan. That's great, as it allowed us to have much more room for negotiations than if we had a higher price cap. This helped us choose to close our first enterprise customer only two weeks after launching.
To handle subscriptions we use Chargebee, a wrapper around Stripe that allows us to easily manage customers, coupons, taxes, invoices, and plans.
Today, three months after launch, we make around $2,500 per month. We are really happy about this number but considering that half of it comes from just two customers, we know our current MRR is fragile.
We've read countless articles on pricing and we know how important it is. Our pricing has not changed since launch and there are probably many things to do to optimize it. But for now we're happy with the result and I don't think we will change our plan before we hit $5k MRR.
What are your goals for the future?
Right now, our only concern is to reach ramen profitability as soon as possible. Once ScrapingBee reaches ramen profitability both Kevin and I will be able to live from its revenue. This ramen threshold, for us, is at $5,000, so our number one priority is to get as many clients as we can to reach it. We know it will be difficult, but we hope to reach that goal early in 2020.
It also means that we'll need to keep doing a lot of content marketing in order to boost both our SEO and our traffic. We have plenty of content in the works and can't wait to share it. We really want to create a community around people who are interested in scraping, but we're still wrapping our heads around how to do this the right way.
What are the biggest challenges you’ve faced and obstacles you’ve overcome?
Kevin and I both have technical backgrounds; we were used to fixing problems with asynchronous solutions.
What I mean by that is that when you find a bug, you deploy a fix, and instantaneously the problem is fixed. When you want to build a new feature, even if you take some time building it, once you deploy your code, the feature is live for everyone. Instant gratification is a common thing in the engineering world, but not in the marketing world.
In the marketing world, there can be a lot of delays before you can see the impact of your actions.
Of course, sometimes, your blog post or your ads will bring a lot of traffic, but most of the efforts you make in the marketing areas are mid- or long-term efforts. And this is especially true when you are building your product from scratch, because you won't observe huge variation in traffic or conversion in the days following your change.
Our SEO efforts took a month to have an effect on our Google ranking and it took at least a month to be sure that our tutorials and email campaigns improved conversions.
We had to learn to be patient and not expect instant gratification for every effort we made. One cliché motivational sentence that resonated a lot with us at that time was: "Everyone tends to overestimate what they can do in one day and underestimate what they can do in one year."
Have you found anything particularly helpful or advantageous?
Our biggest mistake with PricingBot was that we tried to build a product for an audience we didn't know and that didn't know us.
With ScrapingBee, our targets were developers and scraper enthusiasts and we knew who those people were and what they liked.
We also both have personal technical blogs that bring almost 20k visitors per month.
Those two points helped us a lot.
On the marketing side of things, I've read lots of books and blog posts about it but if I could apply only one piece of advice, it would be this one from "Traction" by Gabriel Weinberg and Justin Mares. What they basically say is that at the beginning, it is easy to lose a lot of time and energy trying every different acquisition channel (SEO, ads, content marketing, ...) out there. What you should do instead is find one channel that works well, or well enough, and stick with it to make the most out of it before exploring other solutions. At least at the beginning.
For ScrapingBee we did exactly that. 90% of our marketing effort is content marketing, and so far it's worked like a charm. Of course in the future, we'll try other things, but for now, we're glad we stuck with it.
The second book that really helped me was "Hello Startup" by Yevgeniy Brikman. It's a technical book that explains all the things you should take care of, product-wise, to build a maintainable and scalable product. I read it five years ago and learned a lot from it, especially for someone like me who, at that time, had never worked in a big company with a top-notch engineering team.
Of course, Indie Hackers was also a key part of our success. Kevin introduced me to Indie Hackers back in 2016 and it was eye-opening. Back in the day, I thought that incubators and VC funds were mandatory to build a sustainable tech product. Indie Hackers showed me that I could not be more wrong. I read almost every interviews at the time and learned a lot about MVPs, marketing strategy, monetizing early, Product Hunt... the list goes on!
What’s your advice for indie hackers who are just starting out?
I dont feel really comfortable giving fellow Indie Hackers advice, as it feels like ScrapingBee is only now reaching a tipping point where we can say that it's not a failure, but not yet a success.
Still if I had to try, I'd say that if what you have in mind already exists, just go for it. If the competition is good, it means that there's demand for the problem you are solving. if you have doubts about it just look at all the email marketing tools that launche each week on Product Hunt.
Go for experimentation over assumption. It's very difficult to know when this feature will be a success or not, or if an acquisition channel will be efficient or not. Try to apply the "MVP" wisdom to every part of your product as often as possible.
Talk a lot to your early customers. Don't be afraid to spend an hour on the phone with them to understand who they are and what they need. In order to do that, we offer additional API calls (10x the free plan) to people who accept to spend 15 minutes on the phone with us.
We're still doing it and just had our 60th call!
Where can we go to learn more?
If you want to learn more about scraping, in general, do not hesitate to take a look at our blog.
We also document every major milestone we reach on our IH product page and are currently building scraping community on Twitter and Linkedin.
Don't hesitate to ask me any questions, either here or by email at pierre@scrapingbee.com. I'll try to answer them ASAP!

Hi Pierre, I am Belal Amin, and I beleive that I have a great product that will be of a great interest for you, and its free. it will help you manage your development team and get you funded. please contact me at belalmostafa30@gmail.com or reply to this comment so that I can show you a demo for the project
Great interview and awesome project. I really liked the content marketing phases in the interview. It is going to be really useful for me at some time in the future... :)
Thank you ! Glad you liked it!
This seems fine for the casual hobbyist or someone looking for low volume data for a small homework project perhaps, but the pricing is totally out of touch with the market for anything of scale.
And yet we have many enterprise client. I never though that competing on the price was a good strategy. We offer top-notch customer support and expertise related to scraping needs, so I don't mind being a bit more expensive, but more importantly, our clients don't mind either.
Well - you're pulling in $2.5k MRR, half of which is from two customers. Maybe our idea of "scale" just differs significantly.
Thank you for sharing. 😊
Thank YOU for reading ! Hope you liked it :)
Thanks for the interview. ScrapingBee looks great and well launched. Thanks for https://www.chargebee.com as well.
As I'm also running an API service through a marketplace (RapidAPI), deployed on Heroku. However, they take %20 from each customer and have a lot of problems. I was thinking to build my own server on VPS.
I assume you are using API Gateway for rate limiting, etc. Do you guys use AWS's API Gateway? and how is it working for you?
Thanks
Hi Onar and thanks for the nice words.
We used to go through API lambda but we would not use API gateway. Rate limiting is done on our end.
We launched on RapidAPI with mixed results, how is it working for you?
Not good :)
As you can see I am very frustrated with them :) I'm not sure at this point it is smart to build my own infrastructure since my revenue isn't much and I'm in an early stage.
What are you doing to prevent abuse?
Can't really talk about it publicly ;) But we keep our eyes wide open for it!
Man, as someone close to 'launching' our first product, this has been really helpful. We're practically going to follow your launch list.
Question: When you wrote your ultimate scraping guide, how did you promote it, and where did you post it?
Hi, thank you very much, I hope it will help you.
We simply sent it to all our subscriber, cross posted it on dev.to and reddit.com.
wow great interview, thx for sharing !
Thank you very much!
This comment was deleted 5 years ago
Hey, thank you very much for the kind words.
I did not know the reason behind Mechanical Turk in the first place, very nice trivia.
Indeed I think there is a big market to transform data into information in the e-commerce industry. But we also thought that those kinds of service were only profitable if you had a very big client with big money and your story seems to tell the same thing :).
About the acquisition, the reason is quite simple. The interview was finished by me almost 3 weeks ago, it was published last week and promoted in the email list only yesterday. PricingBot acquisition was only finalized two days ago. Hence why I could not talk about it in the interview. But I'll write about it soon.
This comment was deleted 5 years ago
Thank you!