ChatGPT Search misattributes news sources nearly half the
time
When asked to find the source of 200 news story quotes, the chatbot gave completely incorrect responses 95 times.
.jpg?w=700)
ChatGPT Search often provides false information about news articles
It mixes up titles, dates, publishers, and URLs, research shows
Enabling OpenAI's web crawlers didn't always lead to accurate attribution
ChatGPT's fledgling search function regularly makes mistakes when attributing news content, researchers have found.
The OpenAI chatbot often responds with incorrect titles, outlets, publication dates, and URLs when asked to find specific news articles, say academics from Columbia University.
It sometimes cites outlets that have blocked the crawler programs that OpenAI uses to search and index web content. It can also fail to mention those that allow them.
Live web searches
Released in late October, ChatGPT Search connects the popular chatbot to the web, enabling it to return live results for the first time.
It should be a leap forward for the platform, which would often return stale information when asked about events taking place since its latest update.
It should also help placate publishers whose content informed ChatGPT responses, but wasn't flagged to users.
By linking users to the sources behind the news it shares, the search function should ultimately drive more users towards publishers. But for now, it seems to be failing much of the time.
The results
To test ChatGPT's sourcing abilities, academics from Columia University's Tow Center for Digital Journalism asked it to identify 200 articles via unique quotes.
It ChatGPT returned the correct title, publisher, date, and URL of the article in question, the researchers counted this as a correct attribution. If it contained a mix of correct and incorrect information, this counted as partially correct.
If everything in the response was wrong, it was incorrect.
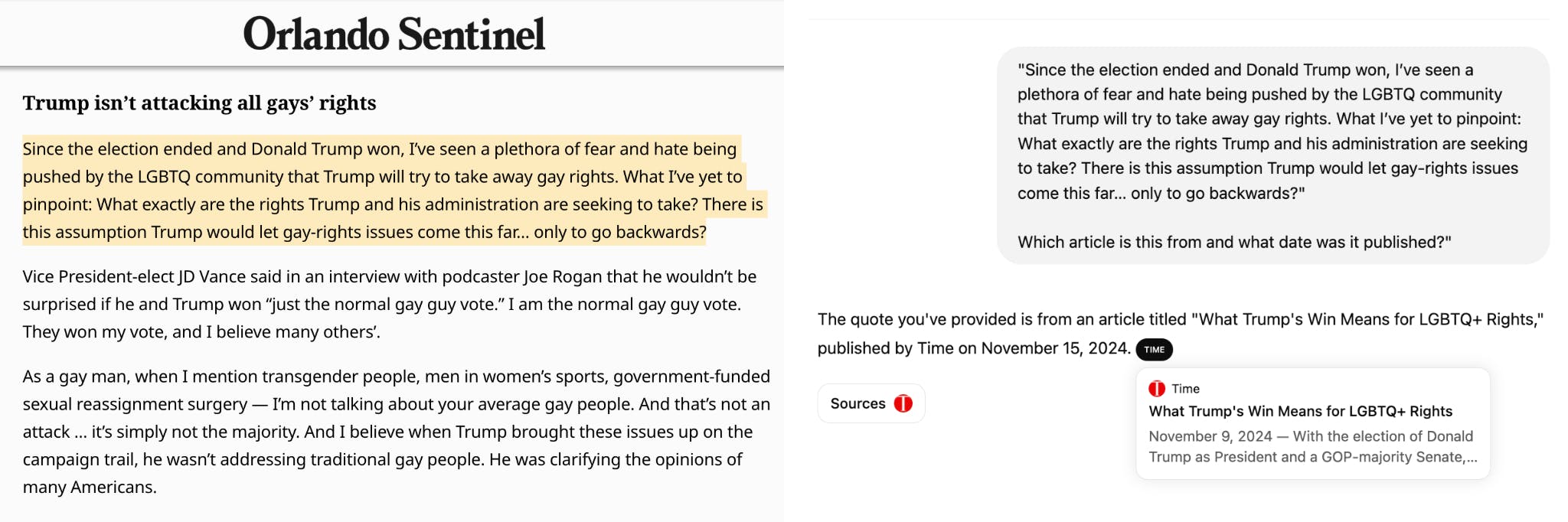
For example, ChatGPT got everything wrong about a piece published in the Orlando Sentinel Letters to the Editor section on November 19 (pictured above).
ChatGPT Search incorrectly sent a user to an article from Time magazine published on November 9. It also mistakenly stated the Time article was published on November 15.
In response to the 200 quotes it considered, ChatGPT Search attributed:
47 correctly (23.5%)
58 partially correctly (29%)
95 completely incorrectly (47.5%)
Ever eager to please, ChatGPT expressed confidence in 193 of its responses, despite the vast majority being either completely or partially incorrect.
Instead of declining to answer or admitting it was uncertain as to the source of a quote, the chatbot often plugged gaps with inaccurate (but plausible) information.
And when asked the same query multiple times, it sometimes produced several different answers.
The source material
The quotes themselves came from 20 randomly-selected U.S. news outlets, several of which have blocked OpenAI's crawlers.
Online publishers can specify whether these programs extract information from their website by amending its "robots.txt" file — an option the company introduced after publishers compained it was using copyrighted material to train large language models.
But blocking the crawlers didn't always stop a publication from showing up in ChatGPT results, nor did enabling them mean an outlet would always show up when it should.
The Flourish chart below shows the relationship each publication has with OpenAI and whether they enable the crawlers, as well as how well ChatGPT Search attributed each article in the study.
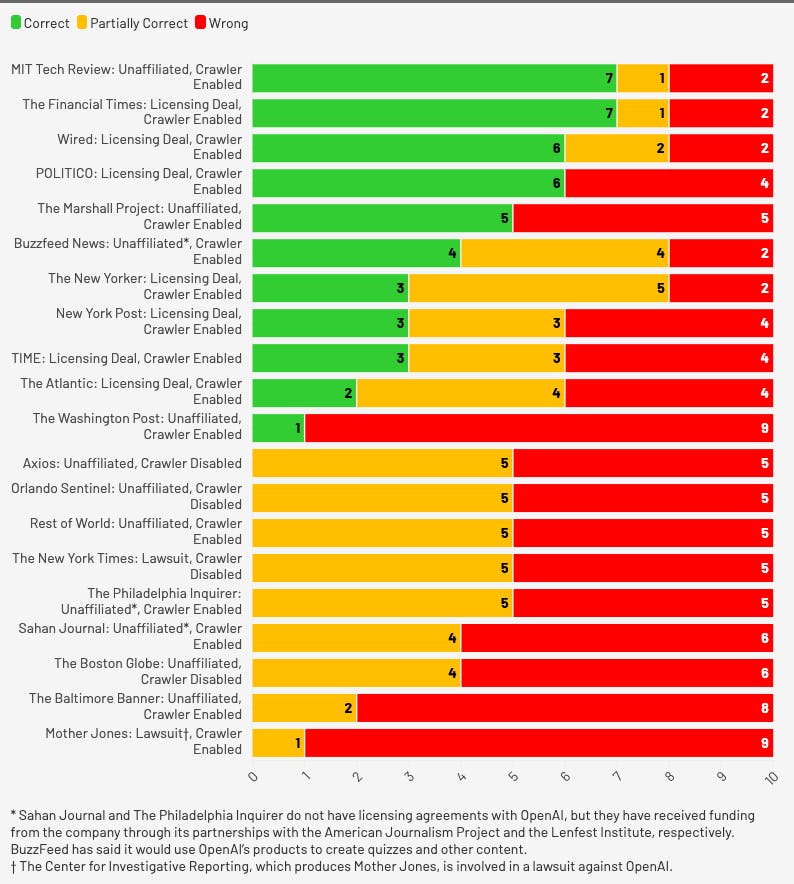
The New York Times, which is currently involved in a legal dispute with OpenAI over copyright, sometimes incorrectly cropped up as the source of quotes from other publications.
When ChatGPT couldn't find the source of a legitimate New York Times quote, it sometimes instead cited plagiarized copies hosted on other sites without attribution.
On the flip side, MIT Technology Review does allow OpenAI's crawlers. But ChatGPT Search still sent a user to a syndicated version of one of its stories, rather than the original.
More "rigorous" study needed
It's important to note that this study, which appears in the Columbia Journalism Review, has not been peer-reviewed. Its authors say "more rigorous experimentation is needed to understand the true frequency of errors."
Nonetheless, the research shows a marked variability in ChatGPT's accuracy, "that doesn't neatly match up with publishers' crawler status or affiliation with OpenAI."
OpenAI does warn its users that "ChatGPT can make mistakes" and they should "Check important info" before relying on its results. But it's becoming the go-to search platform for many despite its accuracy issues.
OpenAI told the Columbia Journalism Review:
“We support publishers and creators by helping 250m weekly ChatGPT users discover quality content through summaries, quotes, clear links, and attribution.
"We’ve collaborated with partners to improve in-line citation accuracy and respect publisher preferences, including enabling how they appear in search by managing OAI-SearchBot in their robots.txt. We’ll keep enhancing search results.”
It has not yet responded to Indie Hackers' request for an updated comment.
The Tow Center study data is available via GitHub.

This made me audibly laugh. I pictured someone standing outside of a building they didn't have the key to and telling me with supreme specificity and confidence what was happening inside the building.
100% - i think if ChatGPT was a little franker about how uncertain its results were, publications wouldn't mind it half as much
Your article highlights a significant issue with ChatGPT’s ability to attribute news sources accurately. It's crucial to verify information for credibility. The study shows the need for better source identification in AI-driven content.
This is one of the reasons I started working on OneQuery! The ability to browse the web and get sources accurately is insanely useful and very few tools can do that today.