What is Time and Space Complexity?
What is time complexity?
Time Complexity could be used to determine if our algorithm will be able to run in the required amount of time by looking at how the runtime grows according to the input. We don't measure the runtime in seconds as it depends on various factors which we don't want to take into consideration. We are interested in the behaviour of an algorithm for a large number of inputs.
How do we measure time complexity?
Big-O notation gives the upper bound of the time complexity of an algorithm.
Let's say we have a function T(n) which gives the runtime of an algorithm where n is the number of inputs. If we can find a function f(n) which when multiplied by c is greater than T(n) then we can say that f(n) upper bounds T(n).
This can be mathematically represented as T(n) <= c \* f(n). And we write it as O(f(n)).
How To Calculate Big O
i\) Break your algorithm into individual operations.
ii\) Calculate the no of times each operation repeats.
iii\) Add everything together.
iv\) Remove the constants multiples.
v\) Drop the lower order terms.
We get rid of all the constant multiples and the lower order terms because they don't contribute much for large values of input. We'll see the steps in the examples below.
What are the different time complexities?
1. Constant time
int average(int a, int b) {
int avg = (a+b)/2; // occurs once
return avg; // occurs once
}
After adding all the values we get :
1 + 1 = 2
In this function, each step occurs once so after adding all the steps we get 2. Which can be written as O(1) because we'll drop all the constant multiples.
Therefore as the input increases, the time taken by the algorithm stays the same.
2. Linear time
int find(int arr[], int key) {
int n = sizeof(arr); // 1
for(int i = 0; i < n; i++) { // n
if(arr[i] == key) // 1
return i; // 1
}
return -1; // 1
}
After adding all the values we get :
1 + n \* (1 + 1)+1
= 2 + 2n
We multiply the values in the for loop i.e (1 + 1) with no of times the loop occurs i.e n. Because the steps inside the for loop will repeat for n number of times.
By dropping the lower order term 2, we get 2n. Then we will drop the constant multiple 2. So the time complexity is given by O(n).
Therefore as input increases, the time taken by the algorithm increases linearly.
3. Quadratic time
int findDuplicates(int array[]) {
int n = sizeof(array); // 1
for (int i = 0; i < n; i++){ // n
for (int j = 0; j < n; j++){ // n
if (i !==j && array[i] == array[j]){ // 1
return i; // 1
}
}
}
return -1; // 1
}
After adding all the values we get :
1 + n \* (n \* (1 + 1 ) ) + 1
= 2 + 2n^2
By dropping the lower order term and the constant multiple we get O(n<sup>2</sup>).
Therefore as input increases, the time taken by the algorithm increases in a quadratic fashion.
4. Logarithmic time
Log is written as log<sub> x</sub> y
log<sub> 2</sub> 8 = 3
You can think of it as how many 2's do we multiply together to get 8. The answer is 3.
Now we'll take a look at binary search. The way this algorithm operates is similar to how we might search for a word in a dictionary. Let's say we open the dictionary somewhere in the middle. If the word we are looking for lies in the left half we ignore the right half and then again split the left half in two.
If we keep on doing this process we'll eventually find the word we are looking for because the words in a dictionary are arranged in alphabetical order. Similarly, if we have a sorted array and we want to look for a value x we can apply binary search.
int binarySearch(int arr[], int x) {
int l = 0;
int h = sizeof(arr)-1;
while (r >= l) {
int mid = l + (r - l) / 2;
// If the element is present at the
// middle itself
if (arr[mid] == x)
return mid;
// If element is smaller than mid, then
// it can only be present in left subarray
if (arr[mid] > x)
h = mid - 1;
// Else the element can only be present
// in right subarray
if (arr[mid]<)x
l = mid + 1;
}
// We reach here when element is not present
// in array
return -1;
}
In this algorithm, the amount of data we have to work with is reduced by half with each iteration.
n/2, n/4, n/8...
Therefore in the worst case, we'll find the element in the last iteration i.e we kept on dividing until only one element was left.
This can be mathematically represented by n / n = 1. The denominator can be represented by a power of 2 as we divided by 2 with every iteration.
Therefore we can write it as n / 2 ^ k = 1 where k is the number of times we divided by 2.
∴ n = 2^k
Because k is the number of times we divided by 2, k will give us the number of iterations it took to get the number in the worst possible case.
The equation n = 2^k can be written as k = log<sub>2</sub>(n). Therefore the time complexity is O(log n).
Therefore as input increases, the time taken by the algorithm increases logarithmically.
Therefore the Time Complexity of a loop is considered as O(logn) if the loop variables is divided / multiplied by a constant amount.
for (int i = 1; i <=n; i *= c) {
// some O(1) expressions
}
for (int i = n; i > 0; i /= c) {
// some O(1) expressions
}
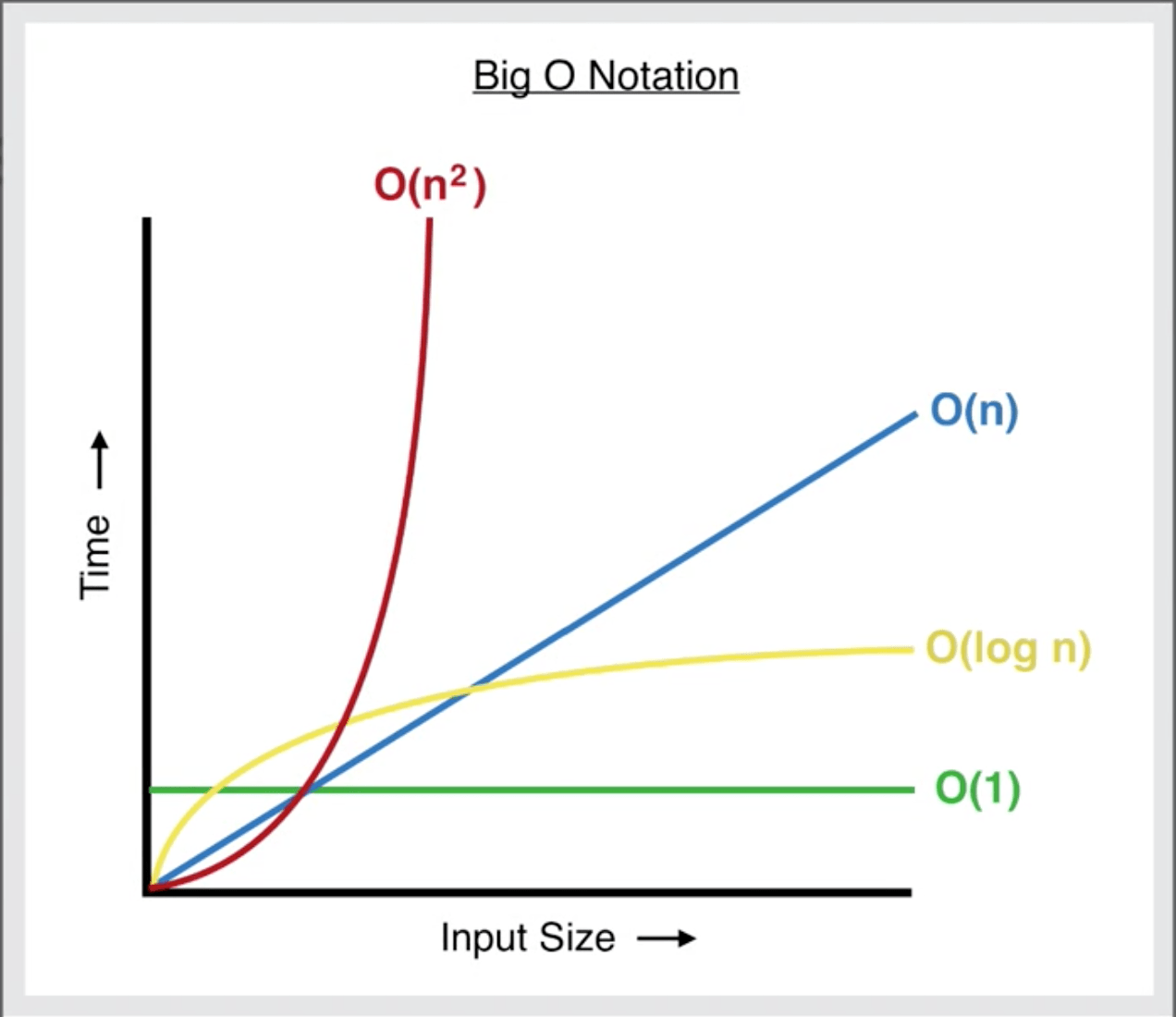
Here we can see the different time complexities we discussed above and how they compare to each other. O(1) is the fastest and O(n<sup>2</sup>) is the slowest.
There are other time complexities as well like O(nlog n), O(c^n), O(n!) which we'll cover in the future posts.
An interesting thing to note is that O(log n) is slower than O(n) for smaller values. But we don't really care about small values we check for the behaviour of the algorithm when the input is large.
What is Space Complexity?
It is same as time complexity but instead of looking at how much more time our algorithm takes as the input grows we look at how much more space does our algorithm consume when we the input grows.
We often optimize for time over space because usually space is not an issue but we want our algorithms to be faster. However, in scenarios like working with embedded systems where we have a memory constrain, space complexity becomes equally important.
Originally posted here

 Aimfox launched on Product Hunt today! 🤩
Aimfox launched on Product Hunt today! 🤩
 Google Whisk - Generate images using images as prompts, not text prompts
Google Whisk - Generate images using images as prompts, not text prompts
 AI is Coming to Fuzen in January! 🚀
AI is Coming to Fuzen in January! 🚀
 40 open-source gems to replace your SaaS subscriptions 🔥 🚀
40 open-source gems to replace your SaaS subscriptions 🔥 🚀